VGGT 在做甚麼




同一場景的多張視角影像
↓
VGGT
single feed-forward · ~1 sec
↓
Cameras
相機參數
Depth Maps
深度圖
Point Maps
點雲圖
Tracks
點追蹤
03/15
四個輸出的作用例子: Figure 1
 1
2
3
4
1
2
3
4
1Cameras
2Point Maps
3Depth Maps
4Tracks
03/15
VGGT 整體架構
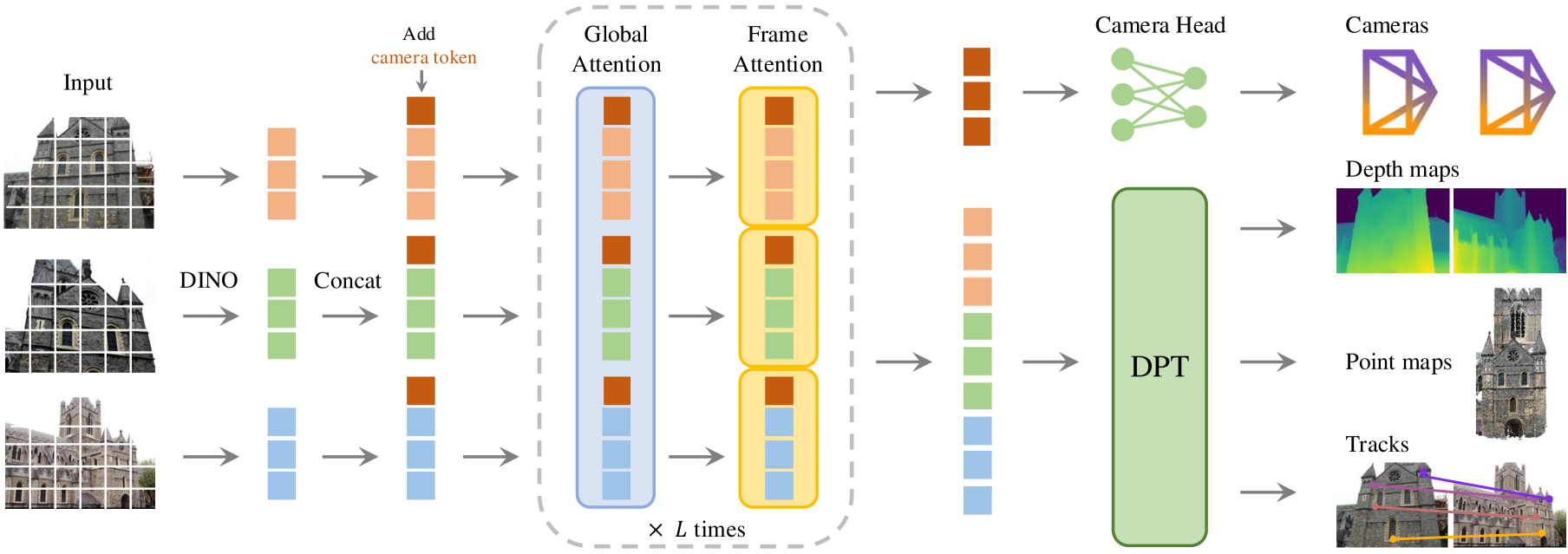
Transformer
decoder + CNN
03/15
ViT (Vision Transformer)

輸入影像
→
flatten +
linear projection
linear projection
patch1
0.21-0.050.84⋮0.13
patch2
-0.180.420.07⋮-0.31
patch3
0.55-0.27-0.11⋮0.46
⋯
patch256
0.080.33-0.49⋮0.22
↓
↓
類別機率分布——選機率最高的當預測:
cat
0.82
tabby cat
0.09
dog
0.04
fox
0.03
rabbit
0.02
11/15
VGGT 架構 — DINO
DINO = ViT,只取 features
12/15
VGGT 架構 — Add Camera Token
12/15
VGGT 架構 — Global + Frame Attention
Global Attention
Frame Attention
12/15
VGGT 架構 — Camera Head
Why attention blocks?
| Component | Numbers | Type |
|---|---|---|
| Rotation (quaternion q) | 4 | Extrinsic |
| Translation (t) | 3 | Extrinsic |
| Field of view (f) | 2 | Intrinsic |
| Total | 9 |
12/15
VGGT 架構 — DPT Head (Decoder)
input image
→
Encoder
壓縮成抽象 features
→
+0.42−0.18+0.71⋮+0.05
features
→
Decoder
還原成具體輸出
→
reconstructed image
12/15
VGGT 架構 — DPT 在這裡做什麼?
Input
Patch tokens
來自 backbone(每張影像一組)
→
DPT Head
Decoder
→
Depth maps
→
Point maps
→
Tracking features
12/15
VGGT demonstration

14/15